Raft协议
Raft 协议是解决分布式领域一致性的著名协议之一,主要包含Leader 选举、日志复制两个部分。
All our nodes start in the follower state. 我们所有的节点都从follower状态开始。 If followers don’t hear from a leader then they can become a candidate. 如果追随者没有收到领导者的消息,那么他们就可以成为候选人。 The candidate then requests votes from other nodes. 然后候选人请求其他节点的投票。 Nodes will reply with their vote. 节点将以投票方式答复。 The candidate becomes the leader if it gets votes from a majority of nodes. 如果候选人获得大多数节点的投票,他将成为领导者。 This process is called Leader Election. 这个过程被称为领导人选举。
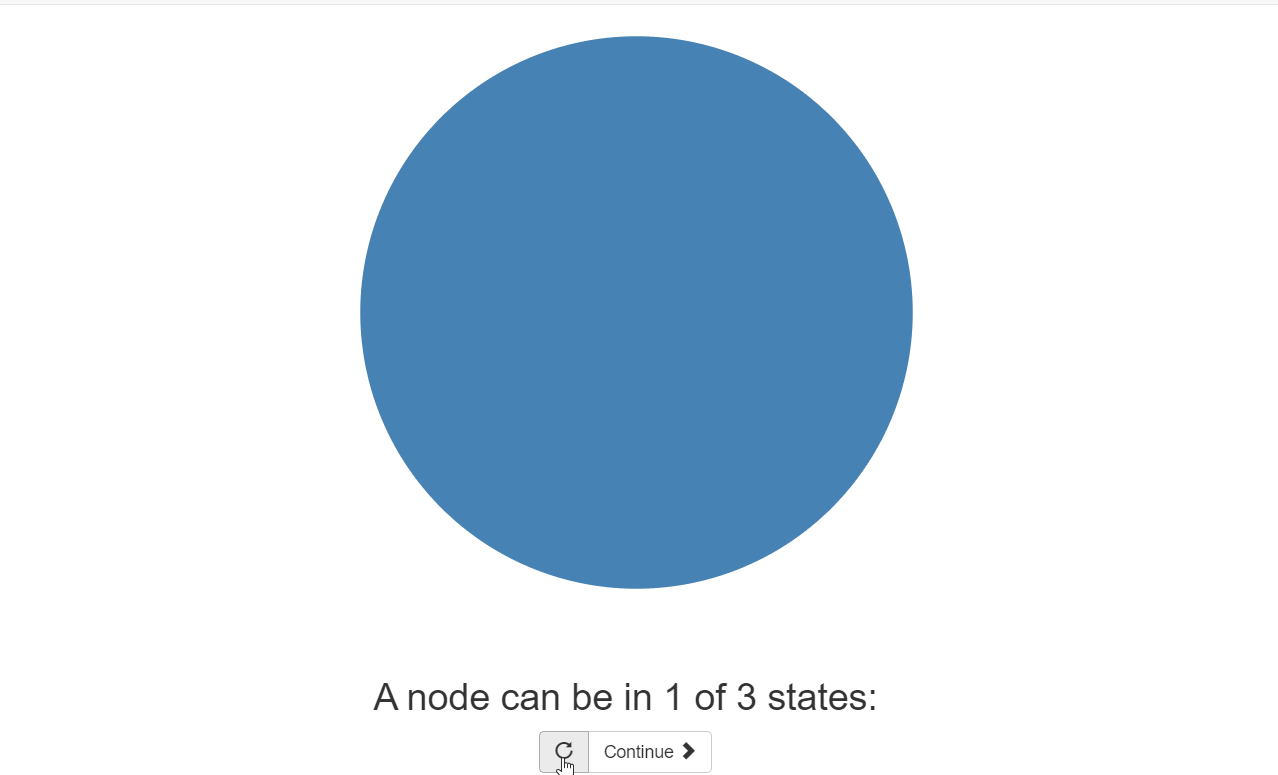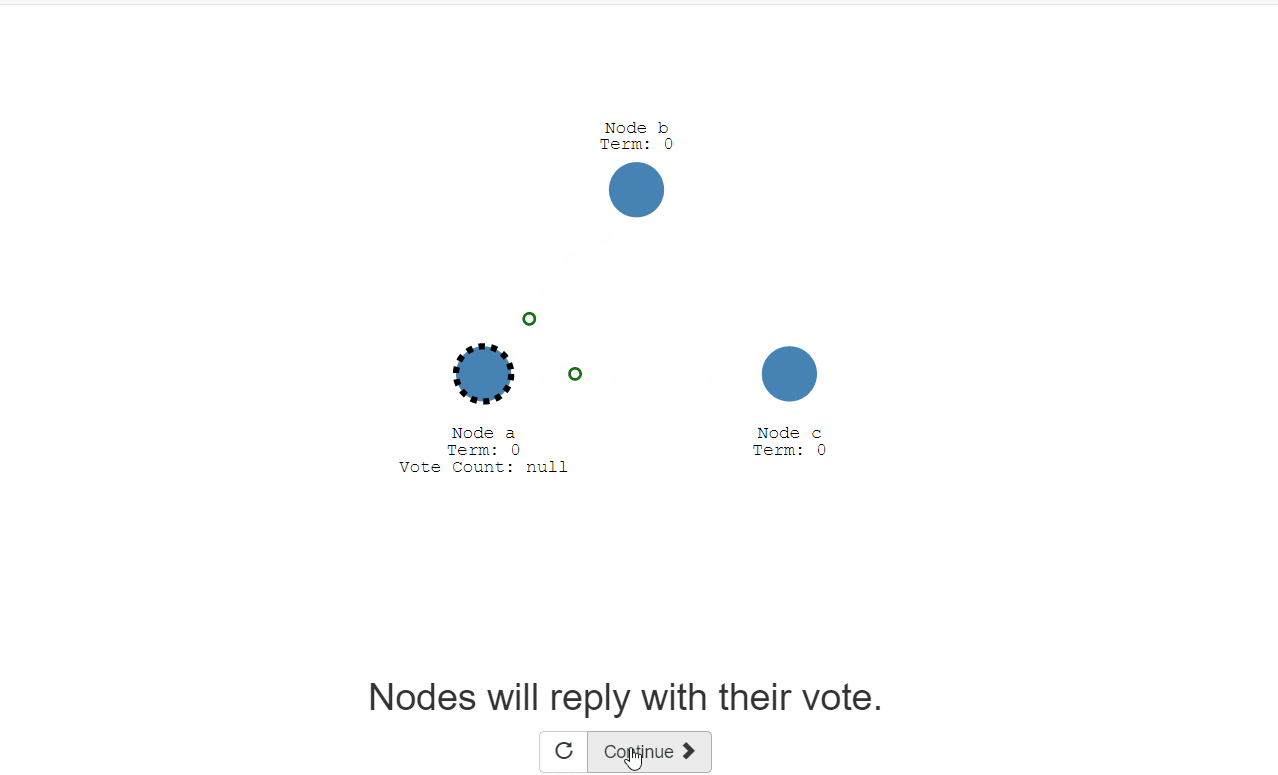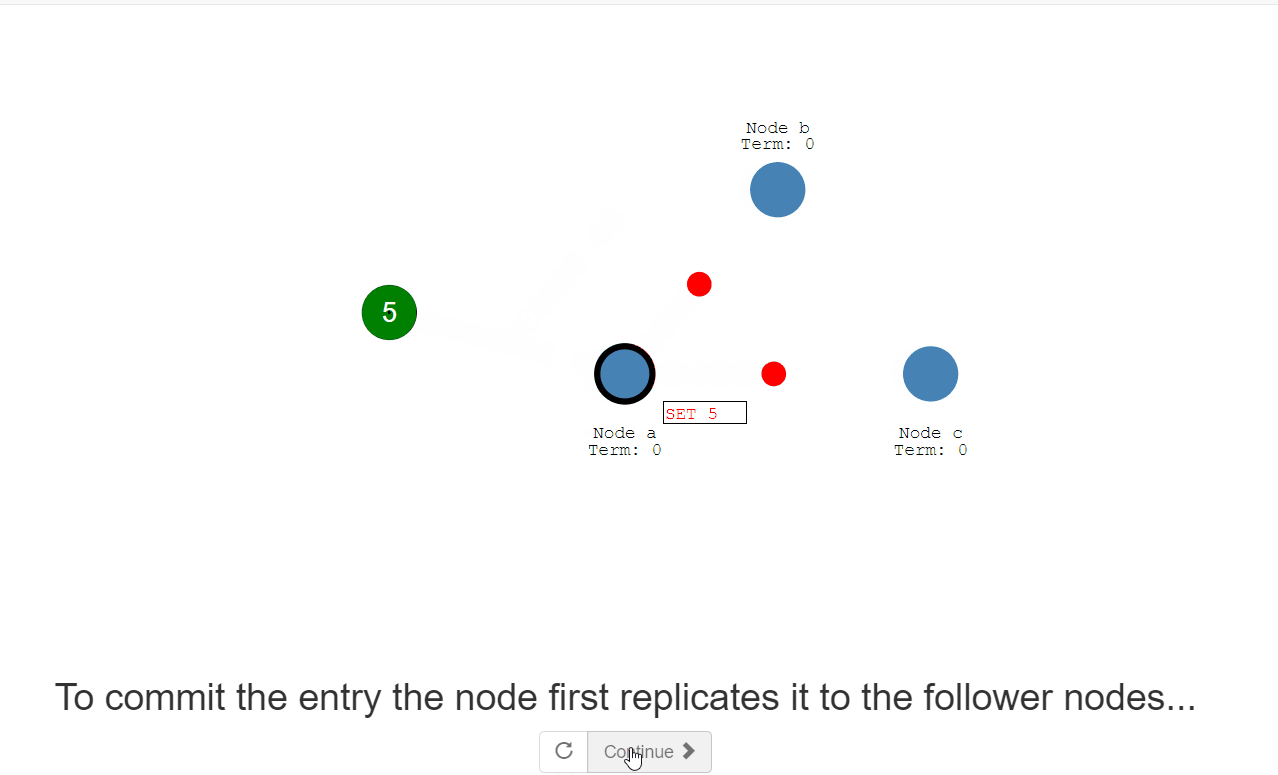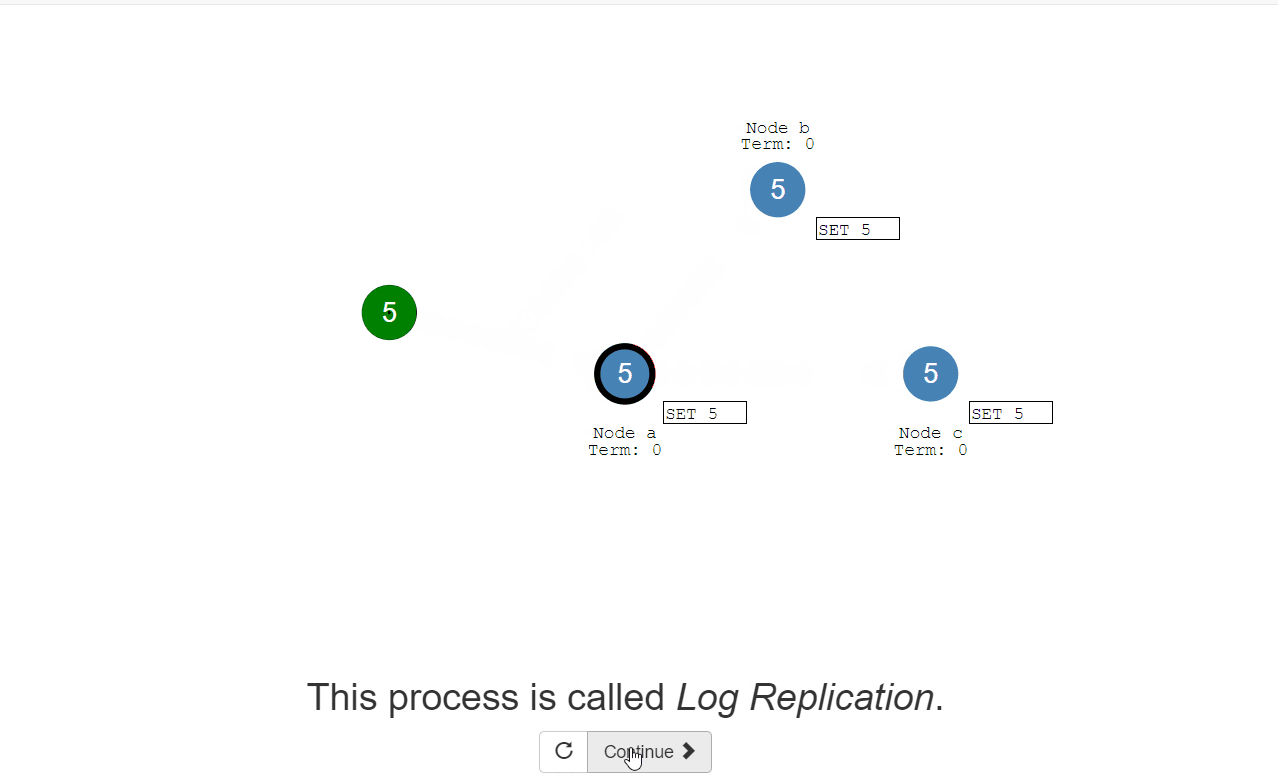
All changes to the system now go through the leader. 对系统的所有更改现在都要经过领导。 Each change is added as an entry in the node’s log. 每个更改都作为一个条目添加到节点的日志中。 This log entry is currently uncommitted so it won’t update the node’s value. 此日志项当前未提交,因此不会更新节点的值。 To commit the entry the node first replicates it to the follower nodes… 要提交条目,节点首先将其复制到follower节点。。。 then the leader waits until a majority of nodes have written the entry. 然后等待,直到大多数节点都写入了条目。 The entry is now committed on the leader node and the node state is “5”. 条目现在在leader节点上提交,节点状态为“5”。 The leader then notifies the followers that the entry is committed. 然后,领导者通知跟随者条目已提交。 The cluster has now come to consensus about the system state. 集群现在已经就系统状态达成共识。 This process is called Log Replication. 这个过程称为日志复制。
Leader选举
节点状态(角色)
-
Follower:跟随者
-
Candidate:候选者
-
Leader:领导者
选择定时器
Follower、Candidate 两个状态时,需要维护一个定时器,每次定时时间从150ms-300ms 直接进行随机,即每个节点的定时过期不一样,Follower 状态时,定时器到点后,触发一轮投票。节点在收到投票请求、Leader 的心跳请求并作出响应后,需要重置定时器。
投票轮次(Team)
Candidate 状态的节点,每发起一轮投票,Team 加一。
投票机制
每一轮一个节点只能为一个节点投赞成票,例如节点A 中维护的轮次为3,并且已经为节点B 投了赞成票,如果收到其他节点,投票轮次为3,则会投反对票,如果收到轮次为4 的节点,是又可以投赞成票的。
成为Leader 条件
必须得到集群中初始数量的大多数,例如如果集群中有3 台集群,则必须得到两票,如果其中一台服务器宕机,剩下的两个节点,还能进行选主吗?答案是可以的,因为可以得到2 票,超过初始集群中3 的一半,所以通常集群中的机器各位尽量为计数,因为4 台的可用性与3 台的一样。
In Raft there are two timeout settings which control elections. 在Raft中有两个超时设置来控制选择。 First is the election timeout. 首先是选举超时。 The election timeout is the amount of time a follower waits until becoming a candidate. 选举超时是追随者等待成为候选人的时间。 The election timeout is randomized to be between 150ms and 300ms. 选举超时随机设置为150ms到300ms之间。 After the election timeout the follower becomes a candidate and starts a new election term… 选举暂停后,追随者成为候选人,并开始新的选举任期。。。 …votes for itself… …为自己投票。。。 …and sends out Request Vote messages to other nodes. …并向其他节点发送请求投票消息。 If the receiving node hasn’t voted yet in this term then it votes for the candidate… 如果接收节点在本任期内还没有投票,那么它将投票给候选人。。。 …and the node resets its election timeout. …节点重置其选举超时。 Once a candidate has a majority of votes it becomes leader. 一旦候选人获得多数票,他就成为领导者。 The leader begins sending out Append Entries messages to its followers. 领导者开始向追随者发送附加条目消息。 These messages are sent in intervals specified by the heartbeat timeout. 这些消息以心跳超时指定的间隔发送。 Followers then respond to each Append Entries message. 跟随者然后响应每个附加条目消息。 This election term will continue until a follower stops receiving heartbeats and becomes a candidate. 这个选举任期将一直持续到一个追随者停止接受心跳并成为候选人。 Let’s stop the leader and watch a re-election happen. 让我们阻止这位领导人,看着重新选举的发生。 Node C is now leader of term 2. 节点C现在是第二任期的领导者。 Requiring a majority of votes guarantees that only one leader can be elected per term. 要求多数选票,保证每届只能选出一名领导人。 If two nodes become candidates at the same time then a split vote can occur. 如果两个节点同时成为候选节点,则可能发生分裂投票。 Let’s take a look at a split vote example… 让我们来看一个分裂投票的例子… Two nodes both start an election for the same term… 两个节点都在同一任期内开始选举。。。 …and each reaches a single follower node before the other. …并且每一个在另一个之前到达一个跟随节点。 Now each candidate has 2 votes and can receive no more for this term. 现在每个候选人都有两张选票,在本任期内不能再获得任何选票。 The nodes will wait for a new election and try again. 节点将等待新的选举并重试。 Node A received a majority of votes in term 5 so it becomes leader. 节点A在第五任期获得多数票,因此成为领先者。
日志复制

Once we have a leader elected we need to replicate all changes to our system to all nodes. 一旦我们选出了一位领导人,我们就需要将系统的所有更改复制到所有节点。 This is done by using the same Append Entries message that was used for heartbeats. 这是通过使用与心跳相同的追加条目消息完成的。 Let’s walk through the process. 我们来看看这个过程。 First a client sends a change to the leader. 首先,客户端向领导者发送更改。 The change is appended to the leader’s log… 更改将附加到领导者日志中。。。 …then the change is sent to the followers on the next heartbeat. …然后在下一次心跳时将更改发送给追随者。 An entry is committed once a majority of followers acknowledge it… 一个条目一旦大多数追随者承认它就被提交。。。 …and a response is sent to the client. …并向客户端发送响应。 Now let’s send a command to increment the value by “2”. 现在让我们发送一个命令,将值增加“2”。 Our system value is now updated to “7”. 我们的系统值现在更新为“7”。 Raft can even stay consistent in the face of network partitions. Raft甚至可以在面对网络分区时保持一致。 Let’s add a partition to separate A & B from C, D & E. 让我们添加一个分区,将A&B与C、D&E分开。 Because of our partition we now have two leaders in different terms. 由于我们的分裂,我们现在有两个不同的领导人。 Let’s add another client and try to update both leaders. 让我们添加另一个客户机并尝试更新两个领导者。 One client will try to set the value of node B to “3”. 一个客户端将尝试将节点B的值设置为“3”。 Node B cannot replicate to a majority so its log entry stays uncommitted. 节点B无法复制到多数,因此其日志项保持未提交状态。 The other client will try to set the value of node C to “8”. 另一个客户端将尝试将节点C的值设置为“8”。 This will succeed because it can replicate to a majority. 这将取得成功,因为它可以复制到大多数人。 Now let’s heal the network partition. 现在让我们修复网络分区。 Node B will see the higher election term and step down. 节点B将看到更高的选举任期和下台。 Both nodes A & B will roll back their uncommitted entries and match the new leader’s log. 两个节点A和B都将回滚其未提交的条目,并匹配新领导的日志。 Our log is now consistent across our cluster. 我们的日志现在在集群中是一致的。