RocketMQ的存储模型
Topic、MessageQueue以及Broker关系
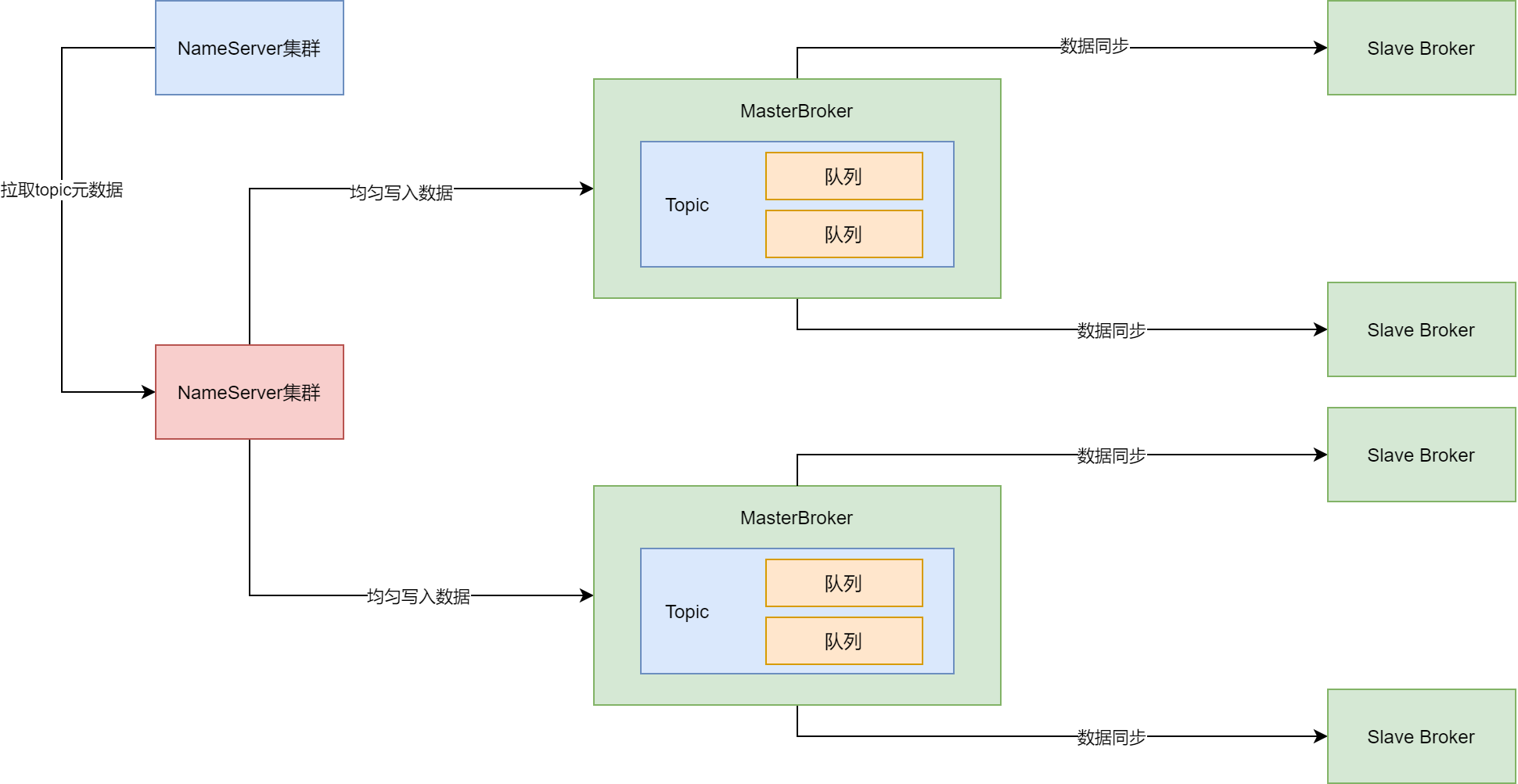
RocketMQ引入了MessageQueue的概念,本质上就是一个数据分片的机制,通过MessageQueue将一个Topic的数据拆分为了很多个数据分片,然后在每个Broker机器上都存储一些MessageQueue。
RocketMQ的存储模型
RocketMQ采用的是混合型的存储结构,即为Broker单个实例下所有的队列共用一个日志数据文件(即为CommitLog)来存储。而Kafka采用的是独立型的存储结构,每个队列一个文件。RocketMQ采用混合型存储结构的缺点在于,会存在较多的随机读操作,因此读的效率偏低。同时消费消息需要依赖ConsumeQueue,构建该逻辑消费队列需要一定开销。
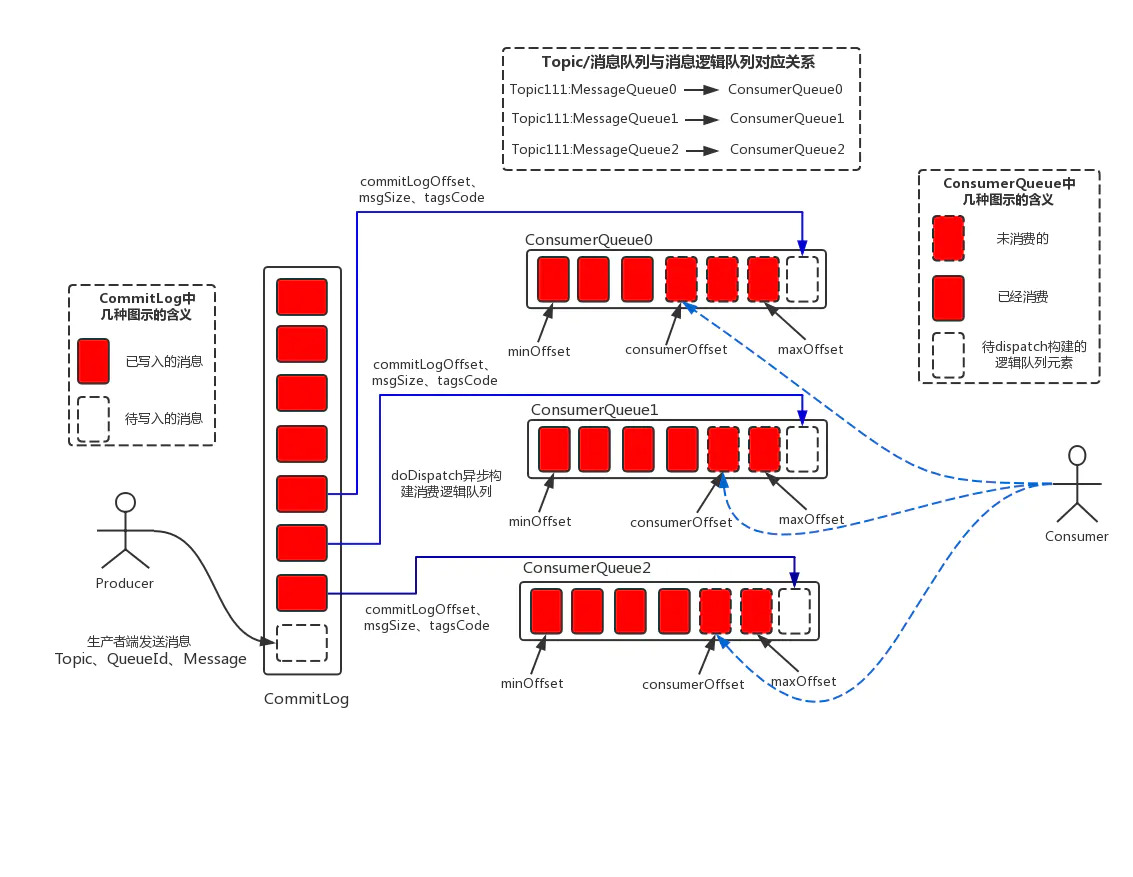
CommitLog消息顺序写入机制
Broker收到消息以后追加写入CommitLog末尾,如果一个CommitLog写满了1GB,就会创建一个新的CommitLog文件。
MessageQueue在数据存储中是体现在哪里呢?
在Broker中,对Topic下的每个MessageQueue都会有一系列的ConsumeQueue文件。
在Broker的磁盘上,会有下面这种格式的一系列文件:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}
- {topic}指代的就是某个Topic
- {queueId}指代的就是某个MessageQueue
- 存储在这台Broker机器上的Topic下的一个MessageQueue,他有很多的ConsumeQueue文件,这个ConsumeQueue文件里存储的是一条消息对应在CommitLog文件中的offset偏移量。
消息写入过程
当你的Broker收到一条消息写入了CommitLog之后,其实他同时会将这条消息在CommitLog中的物理位置,也就是一个文件偏移量,就是一个offset,写入到这条消息所属的MessageQueue对应的ConsumeQueue文件中去。
比如现在这条消息在生产者发送的时候是发送给MessageQueue0的,那么此时Broker就会将这条消息在CommitLog中的offset偏移量,写入到MessageQueue0对应的ConsumeQueue0中去。实际上在ConsumeQueue中存储的每条数据不只是消息在CommitLog中的offset偏移量,还包含了消息的长度,以及tag hashcode,一条数据是20个字节,每个ConsumeQueue文件保存30万条数据,大概每个文件是5.72MB。
所以实际上Topic的每个MessageQueue都对应了Broker机器上的多个ConsumeQueue文件,保存了这个MessageQueue的所有消息在CommitLog文件中的物理位置,也就是offset偏移量。
写入CommitLog文件近乎内存写性能的
Broker是基于OS操作系统的PageCache和顺序写两个机制,来提升写入CommitLog文件的性能的。
数据写入CommitLog文件的时候,其实不是直接写入底层的物理磁盘文件的,而是先进入OS的PageCache内存缓存中,然后后续由OS的后台线程选一个时间,异步化的将OS PageCache内存缓冲中的数据刷入底层的磁盘文件
采用磁盘文件顺序写+OS PageCache写入+OS异步刷盘的策略,基本上可以让消息写入CommitLog的性能跟你直接写入内存里是差不多的,所以正是如此,才可以让Broker高吞吐的处理每秒大量的消息写入
同步刷盘与异步刷盘
异步刷盘模式下,生产者把消息发送给Broker,Broker将消息写入OS PageCache中,就直接返回ACK给生产者了,异步刷盘的的策略下,可以让消息写入吞吐量非常高,但是可能会有数据丢失的风险。
同步刷盘,如果你使用同步刷盘模式的话,那么生产者发送一条消息出去,broker收到了消息,必须直接强制把这个消息刷入底层的物理磁盘文件中,然后才会返回ack给producer,此时你才知道消息写入成功。导致消息写入吞吐量急剧下降,但是可以保证数据不会丢失。