Hystrix简介
什么是Hystrix:
Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
翻译:
在分布式环境中,不可避免地,许多服务依赖关系中的一些将失败。Hystrix是一个库,可通过添加延迟容差和容错逻辑来帮助您控制这些分布式服务之间的交互。Hystrix通过隔离服务之间的访问点、阻止跨它们的级联失败以及提供回退选项来实现这一点,所有这些都会提高系统的整体弹性
基础
设计模式:命令模式(Command Pattern)
命令模式:将客户端对服务直接调用,封装成一个待执行的请求,客户端和请求被封装为一个对象,对于服务方而言,每个不同的请求就是不同的参数,从而让我们可用不同的请求对客户进行参数化;命令模式的最大特征就是把客户端和服务端直接关系,通过命令对象进行解耦,在执行上,可以对请求排队或者记录请求日志,以及支持可撤销的操作。
线程池和信号量隔离
- 线程作为系统运行的基本单位,可以通过划分指定的线程池资源的使用目的,对系统资源进行分离,具备资源限定的能力,进而保护系统;
Semaphore的信号量机制,也能提供资源竞争的隔离作用;
Hystrix运行流程
 流程说明:
流程说明:
- 1:每次调用创建一个新的
HystrixCommand,把依赖调用封装在run()方法中。 - 2:执行execute()/queue做同步或异步调用。
- 3:判断是否使用缓存响应请求,若启用了缓存,且缓存可用,直接使用缓存响应请求。
- 4:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤5。
- 5:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤。
- 6:调用
HystrixCommand的run方法.运行依赖逻辑- 6a:调用出错,进入步骤8。
- 6b:依赖逻辑调用超时,进入步骤8。
- 6c:返回成功调用结果。
- 7:计算熔断器状态,所有的运行状态(成功,失败,拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态。
- 8:getFallback()降级逻辑,以下四种情况将触发getFallback调用:
- (1):run()方法抛出非
HystrixBadRequestException异常; - (2):run()方法调用超时;
- (3):熔断器开启拦截调用;
- (4):线程池/队列/信号量是否跑满;
- 8a:没有实现getFallback的Command将直接抛出异常;
- 8b:fallback降级逻辑调用成功直接返回;
- 8c:降级逻辑调用失败抛出异常;
- (1):run()方法抛出非
- 9:返回执行成功结果。
execute执行过程

调用的路径为execute() -> queue() -> toObservable() -> toBlocking() -> toFuture() -> get().核心的逻辑其实就在toObservable()中
请求缓存(request cache)
Hystrix支持将一个请求结果缓存起来,在同一个请求上下文中,具有相同key的请求将直接从缓存中取出结果,很适合查询类的接口,可以使用缓存进行优化,减少请求开销,从而跳过真实服务的访问请求。
- 构建
RequestContext,可以在拦截器中使用HystrixRequestContext.initializeContext() 和HystrixRequestContext.shutdown()来初始化 RequestContext 和 关闭RequestContext资源。 - 重写
HystrixCommand或HystrixObservableCommand中的getCacheKey() 方法,指定缓存的 key,开启缓存配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class HystrixRequestContextServletFilter implements Filter {
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HystrixRequestContext context = HystrixRequestContext.initializeContext();
try {
chain.doFilter(request, response);
} finally {
context.shutdown();
}
}
}
@Bean
public FilterRegistrationBean indexFilterRegistration() {
FilterRegistrationBean registration = new FilterRegistrationBean(new IndexFilter());
registration.addUrlPatterns("/");
return registration;
}
熔断器

工作原理
- 断路器时间窗内的请求数 是否超过了断路器生效阈值的请求数,
HystrixCommandProperties.circuitBreakerRequestVolumeThreshold()。
举个例子,要求在10s内,经过短路器的流量必须达到20个;在10s内,经过短路器的流量才10个,那么根本不会去判断要不要短路。
-
并且请求错误率超过了请求错误率阈值,
HystrixCommandProperties.circuitBreakerErrorThresholdPercentage()。如果达到了上面的要求,比如说在10s内,经过短路器的流量,达到了30个;同时其中异常的访问数量,占到了一定的比例,比如说60%的请求都是异常(报错,timeout,reject),会开启短路。 -
然后断路器从close状态转换到open状态。
-
断路器打开的时候,所有经过该断路器的请求全部被短路,不调用后端服务,直接走fallback降级。
-
经过了一段时间之后,
HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds(),会half-open,让一个请求经过短路器,看能不能正常调用。如果调用成功了,那么就自动恢复,转到close状态。circuit breaker短路器配置:
key值 说明 默认值 circuitBreaker.enabled是否开启断路器 true circuitBreaker.requestVolumeThreshold断路器启用请求数阈值 20 circuitBreaker.sleepWindowInMilliseconds断路器启用后的睡眠时间窗 5000(ms) circuitBreaker.errorThresholdPercentage断路器启用失败率阈值 50% circuitBreaker.forceOpen是否强制将断路器设置成开启状态 false circuitBreaker.forceClosed是否强制将断路器设置成关闭状态 false
circuitBreaker.enabled:控制短路器是否允许工作,包括跟踪依赖服务调用的健康状况,以及对异常情况过多时是否允许触发短路,默认是true,HystrixCommandProperties.Setter().withCircuitBreakerEnabled(boolean value)circuitBreaker.requestVolumeThreshold:设置一个rolling window,滑动窗口中,最少要有多少个请求时,才触发开启短路,举例来说,如果设置为20(默认值),那么在一个10秒的滑动窗口内,如果只有19个请求,即使这19个请求都是异常的,也是不会触发开启短路器的,HystrixCommandProperties.Setter().withCircuitBreakerRequestVolumeThreshold(int value)。circuitBreaker.sleepWindowInMilliseconds:设置在短路之后,需要在多长时间内直接reject请求,然后在这段时间之后,再重新导holf-open状态,尝试允许请求通过以及自动恢复,默认值是5000毫秒,HystrixCommandProperties.Setter().withCircuitBreakerSleepWindowInMilliseconds(int value)。circuitBreaker.errorThresholdPercentage:设置异常请求量的百分比,当异常请求达到这个百分比时,就触发打开短路器,默认是50,也就是50%,HystrixCommandProperties.Setter().withCircuitBreakerErrorThresholdPercentage(int value)。circuitBreaker.forceOpen:如果设置为true的话,直接强迫打开短路器,相当于是手动短路了,手动降级,默认false,HystrixCommandProperties.Setter().withCircuitBreakerForceOpen(boolean value)。circuitBreaker.forceClosed:如果设置为ture的话,直接强迫关闭短路器,相当于是手动停止短路了,手动升级,默认false,HystrixCommandProperties.Setter().withCircuitBreakerForceClosed(boolean value)。
滑动窗口
Hystrix对系统指标的统计是基于时间窗模式的:
时间窗:最近的一个时间区间内,比如前一小时到现在,那么时间窗的长度就是
1小时; 桶:桶是在特定的时间窗内,等分的指标收集的统计集合;比如时间窗的长度为1小时,而桶的数量为10,那么每个桶在时间轴上依次排开,时间由远及近,每个桶统计的时间分片为1h / 10 = 6 min6分钟。一个桶中,包含了成功数、失败数、超时数、拒绝数四个指标。
在系统内,时间窗会随着系统的运行逐渐向前移动,而时间窗的长度和桶的数量是固定不变的,那么随着时间的移动,会出现较久的过期的桶被移除出去,新的桶被添加进来,如下图所示:
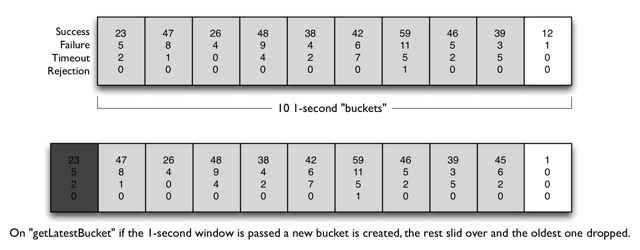
滑动窗口配置
| key | 说明 | 默认值 |
|---|---|---|
metrics.rollingStats.timeInMilliseconds |
时间窗的长度 | 10000(ms) |
metrics.rollingStats.numBuckets |
桶的数量,需要保证timeInMilliseconds % numBuckets =0 |
10 |
metrics.rollingPercentile.enabled |
是否统计运行延迟的占比 | true |
metrics.rollingPercentile.timeInMilliseconds |
运行延迟占比统计的时间窗 | 60000(ms) |
metrics.rollingPercentile.numBuckets |
运行延迟占比统计的桶数 | 6 |
metrics.rollingPercentile.bucketSize |
百分比统计桶的容量,桶内最多保存的运行时间统计 | 100 |
metrics.healthSnapshot.intervalInMilliseconds |
统计快照刷新间隔 | 500 (ms) |
线程池和信号量区别

线程池的好处:
- 该应用程序完全可以不受失控的客户端库的威胁。即使某一个依赖的线程池已满也不会影响其他依赖的调用。
- 应用程序可以低风险的接受新的客户端库的数据,如果发生问题,它会与出问题的客户端库所隔离,不会影响其他依赖的任何内容。
- 当失败的客户端服务恢复时,线程池将会被清除,应用程序也会恢复,而不至于使得我们整个Tomcat容器出现故障。
- 如果一个客户端库的配置错误,线程池可以很快的感知这一错误(通过增加错误比例,延迟,超时,拒绝等),并可以在不影响应用程序的功能情况下来处理这些问题(可以通过动态配置来进行实时的改变)。
- 如果一个客户端服务的性能变差,可以通过改变线程池的指标(错误、延迟、超时、拒绝)来进行属性的调整,并且这些调整可以不影响其他的客户端请求。
- 除了隔离的优势之外,拥有专用的线程池可以提供内置的请求任务的并发性,可以在同步客户端上构建异步门面。
线程池的缺点:
- 每个 command 的执行都依托一个独立的线程,会进行排队,调度,还有上下文切换;
- 如果线程隔离过多,会导致用于接收请求进行处理的线程减少,降低系统吞吐量;
- 增加系统额外开销;
信号量的好处:
- 基于信号量的隔离,利用JVM的原子性CAS操作,避免了资源锁的竞争,省去了线程池开销,效率非常高;
信号量的缺点
- 本质上基于信号量的隔离是同步行为,所以无法做到超时熔断,所以服务方自身要控制住执行时间,避免超时。
使用场景:
- 线程池:适合绝大多数的场景,99%的场景,对依赖服务的网络请求的调用和访问,timeout问题;
- 信号量:适合不是对外部依赖的访问,不涉及任何的网络请求,而是对内部的一些比较复杂的业务逻辑,做信号量的普通限流;
设计原则
- 阻止任何一个依赖服务耗尽所有的资源,比如tomcat中的所有线程资源;
- 避免请求排队和积压,采用限流和fail fast来控制故障;
- 提供fallback降级机制来应对故障;
- 使用资源隔离技术,比如bulkhead(舱壁隔离技术),swimlane(泳道技术),circuit breaker(短路技术),来限制任何一个依赖服务的故障的影响;
- 通过近实时的统计/监控/报警功能,来提高故障发现的速度;
- 通过近实时的属性和配置热修改功能,来提高故障处理和恢复的速度;
- 保护依赖服务调用的所有故障情况,而不仅仅只是网络故障情况;
设计实现
- 通过
HystrixCommand或者HystrixObservableCommand来封装对外部依赖的访问请求,这个访问请求一般会运行在独立的线程中,资源隔离; - 对于超出我们设定阈值的服务调用,直接进行超时,不允许其耗费过长时间阻塞住。这个超时时间默认是99.5%的访问时间,但是一般我们可以自己设置一下;
- 为每一个依赖服务维护一个独立的线程池,或者是semaphore,当线程池已满时,直接拒绝对这个服务的调用;
- 对依赖服务的调用的成功次数,失败次数,拒绝次数,超时次数,进行统计;
- 如果对一个依赖服务的调用失败次数超过了一定的阈值,自动进行熔断,在一定时间内对该服务的调用直接降级,一段时间后再自动尝试恢复;
- 当一个服务调用出现失败,被拒绝,超时,短路等异常情况时,自动调用fallback降级机制;
- 对属性和配置的修改提供近实时的支持;
timeout超时设置
-
execution.isolation.thread.timeoutInMilliseconds:手动设置timeout时长,一个command运行超出这个时间,就被认为是timeout,然后将hystrix command标识为timeout,同时执行fallback降级逻辑,默认是1000,也就是1000毫秒。HystrixCommandProperties.Setter().withExecutionTimeoutInMilliseconds(int value) -
execution.timeout.enabled:控制是否要打开timeout机制,默认是true。HystrixCommandProperties.Setter().withExecutionTimeoutEnabled(boolean value)